

AI Is Reading Your Content and Recommending Your Competitors


A field sales software company is being cited as a source by AI search tools in 30% of buyer queries about their category.
Their brand is mentioned in zero of those responses.
The AI reads their blog about territory management, learns from it, and recommends three of their competitors by name. Their content is doing the work. Their competitors are getting the credit.
At Virayo, we started measuring it.
Here is a cross-section from 20 B2B SaaS verticals:
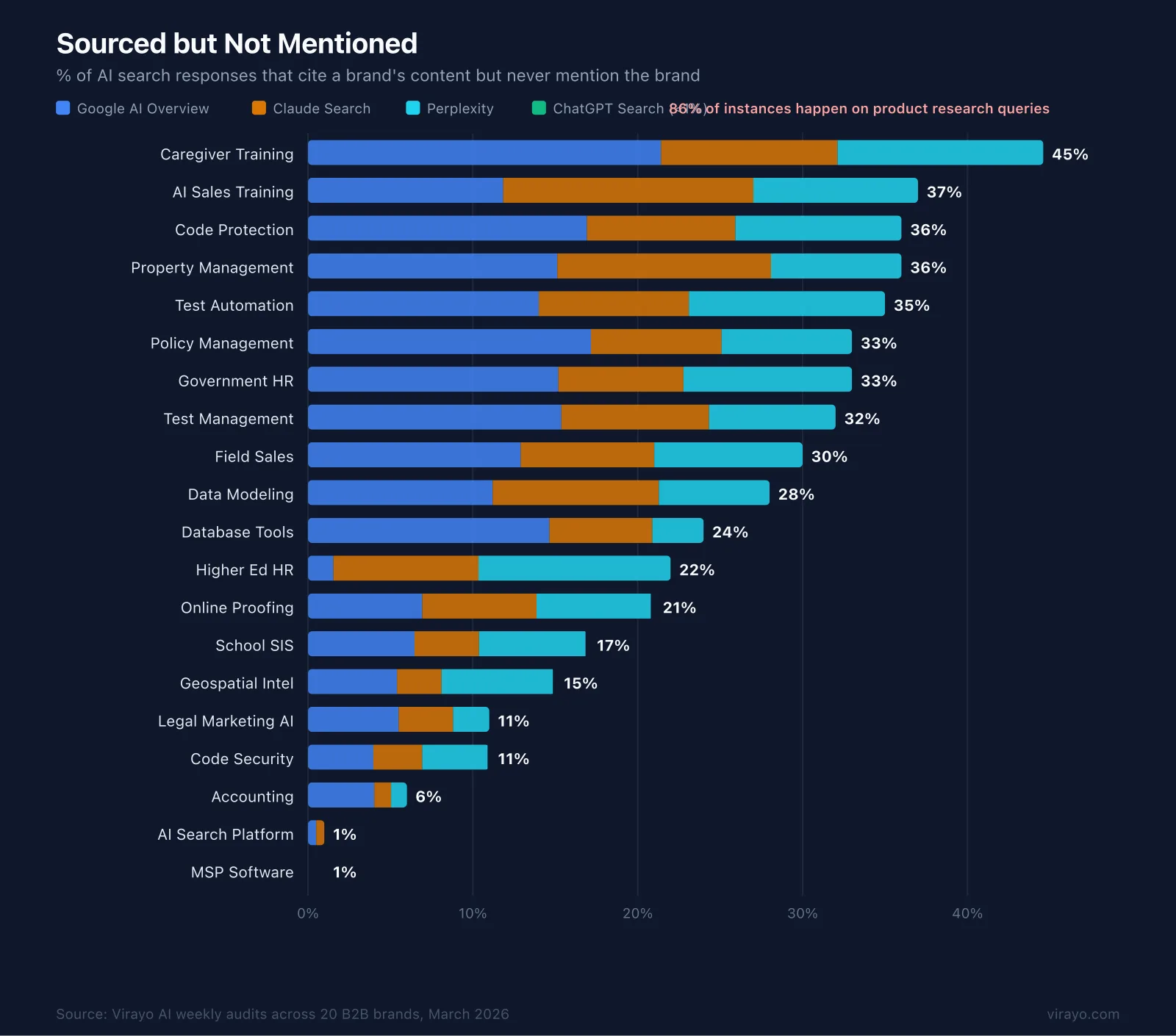
That 45x variance is structural. And it's a pipeline problem. 86% of these instances happen on product research queries, searches where a buyer is evaluating tools in the category. This is where shortlists form. Every response that cites your expertise and recommends someone else is a buyer who just got handed a shortlist you're not on.
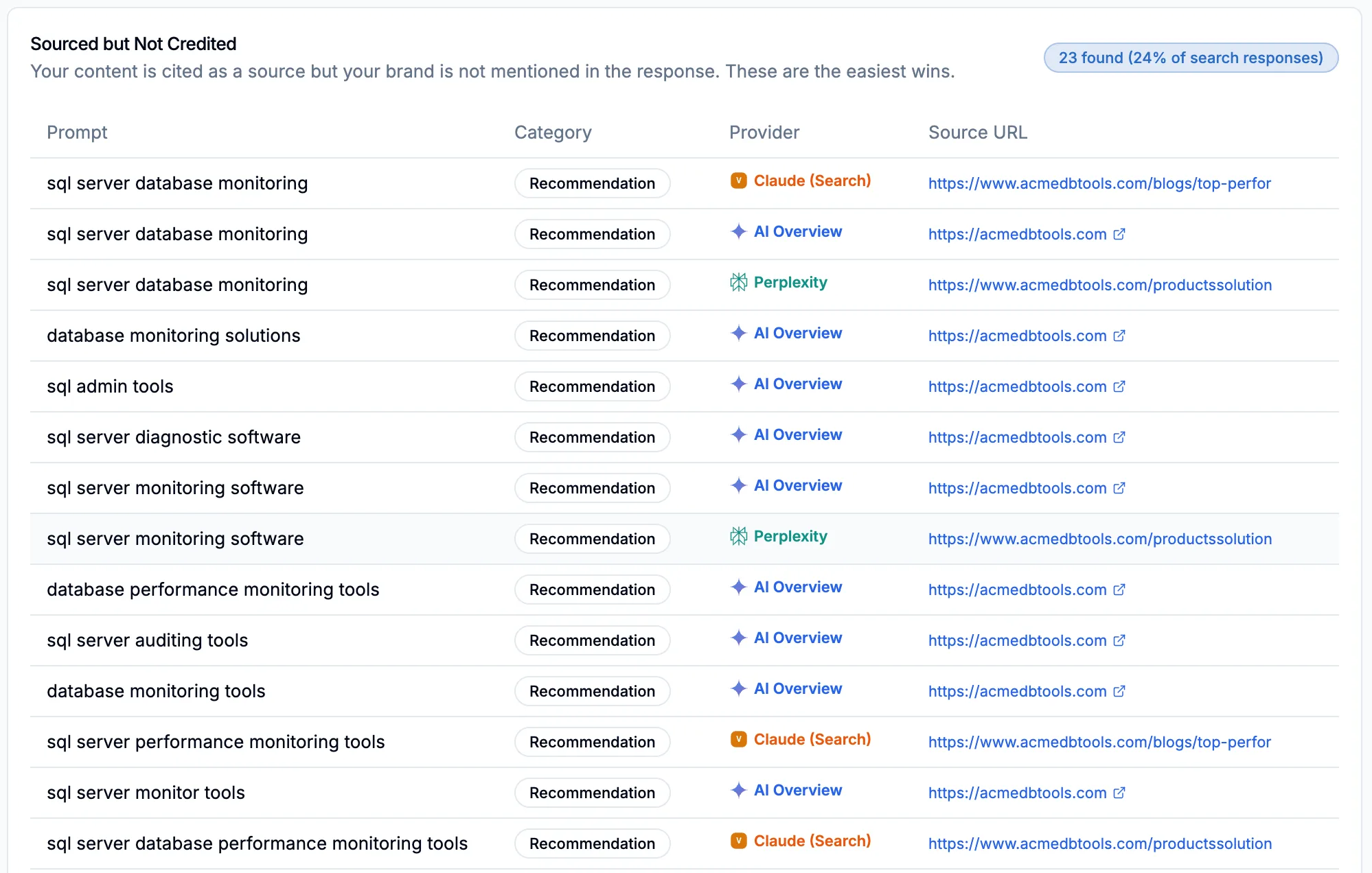
A database tools company is a clear example. They wrote the buyer's guide. AI uses it to build the answer. Then recommends their competitors by name. The content earns a citation. The brand doesn't earn a mention.
This compounds. AI mentions are reinforcement loops. Every response that names your competitor and not you reinforces that pattern across the web. Buyers share AI recommendations internally. Those recommendations shape purchase decisions that generate reviews, case studies, and coverage. All of which feed back into the data these AI tools retrieve and learn from. Six months from now, the gap is wider. Twelve months from now, you're not just behind. You're actively training AI to recommend someone else using your own content as the source material.
Why This Happens
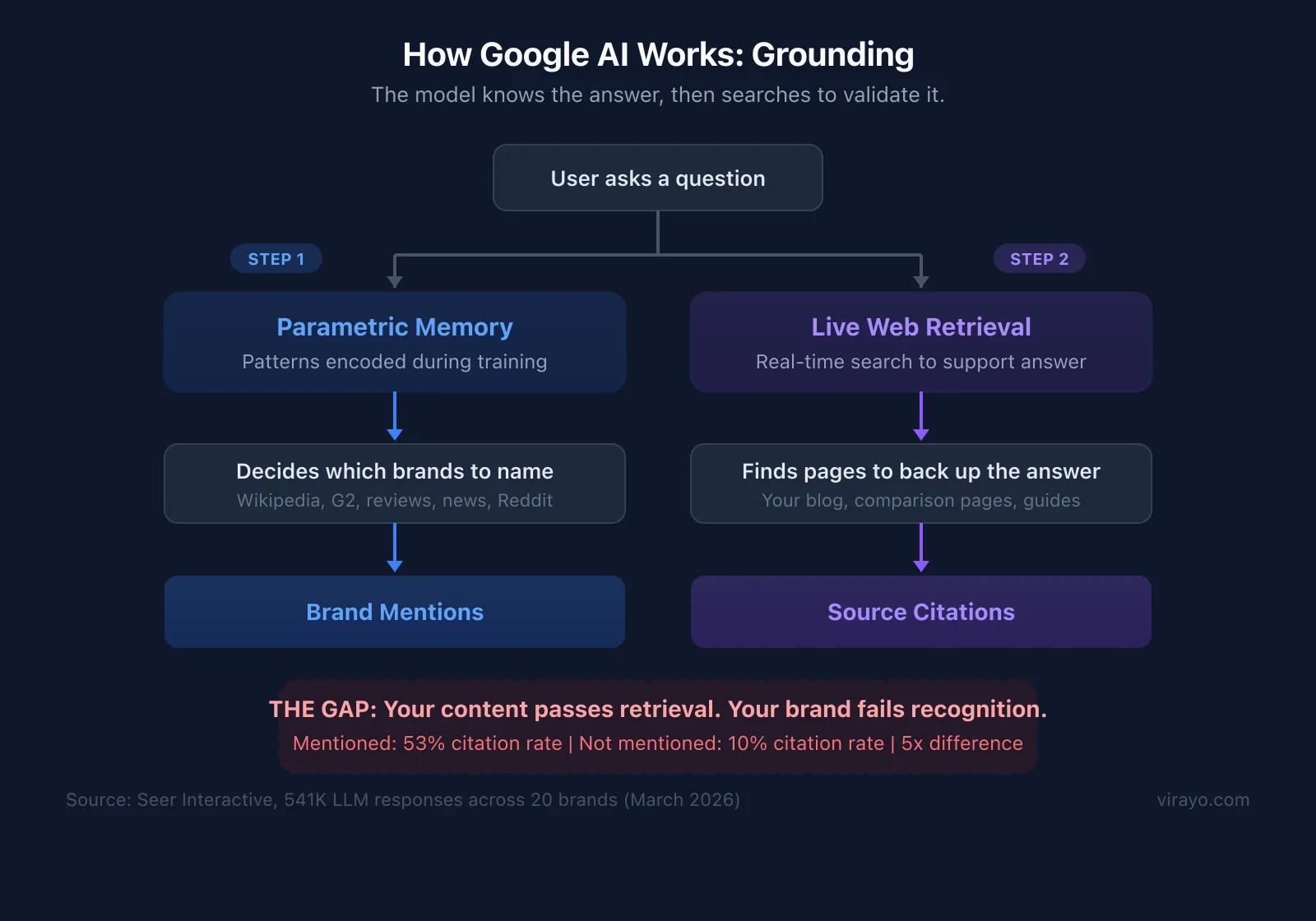
Seer Interactive studied 541,000 LLM responses across 20 brands and 6 platforms and found that brand mentions and citations are decoupled. They measured a 5x gap: when a brand IS mentioned, its citation rate is 53%. When it is NOT mentioned, citation rate drops to 10%. Your content passes the retrieval threshold. Your brand does not clear the mention threshold.
The community is actively debating why. Rand Fishkin, Britney Muller, and Leigh McKenzie at Semrush have all weighed in. We have two working theories about the search architectures behind this.
The first is what the industry is calling post-hoc rationalization, and it maps to Google's architecture. Google owns the index and trained its model on that same data. The model already knows what content exists before it generates a response. Brand mentions come from patterns the model learned from the very pages it will later cite. The grounding queries find specific URLs to attach as citations, but the answer was already formed. The model shapes the answer, then backfills citations.
The second is the architecture behind ChatGPT, Perplexity, and Claude. These tools work differently. The model generates search queries based on the user's prompt, retrieves content into context, and then generates the answer using both what it found and what it already knows from training.
This is the search-first model (retrieval-augmented generation, or RAG). The retrieved content shapes the answer structure and facts. The model's training data biases which brands fill the slots. Both influence the output in a single generation pass.
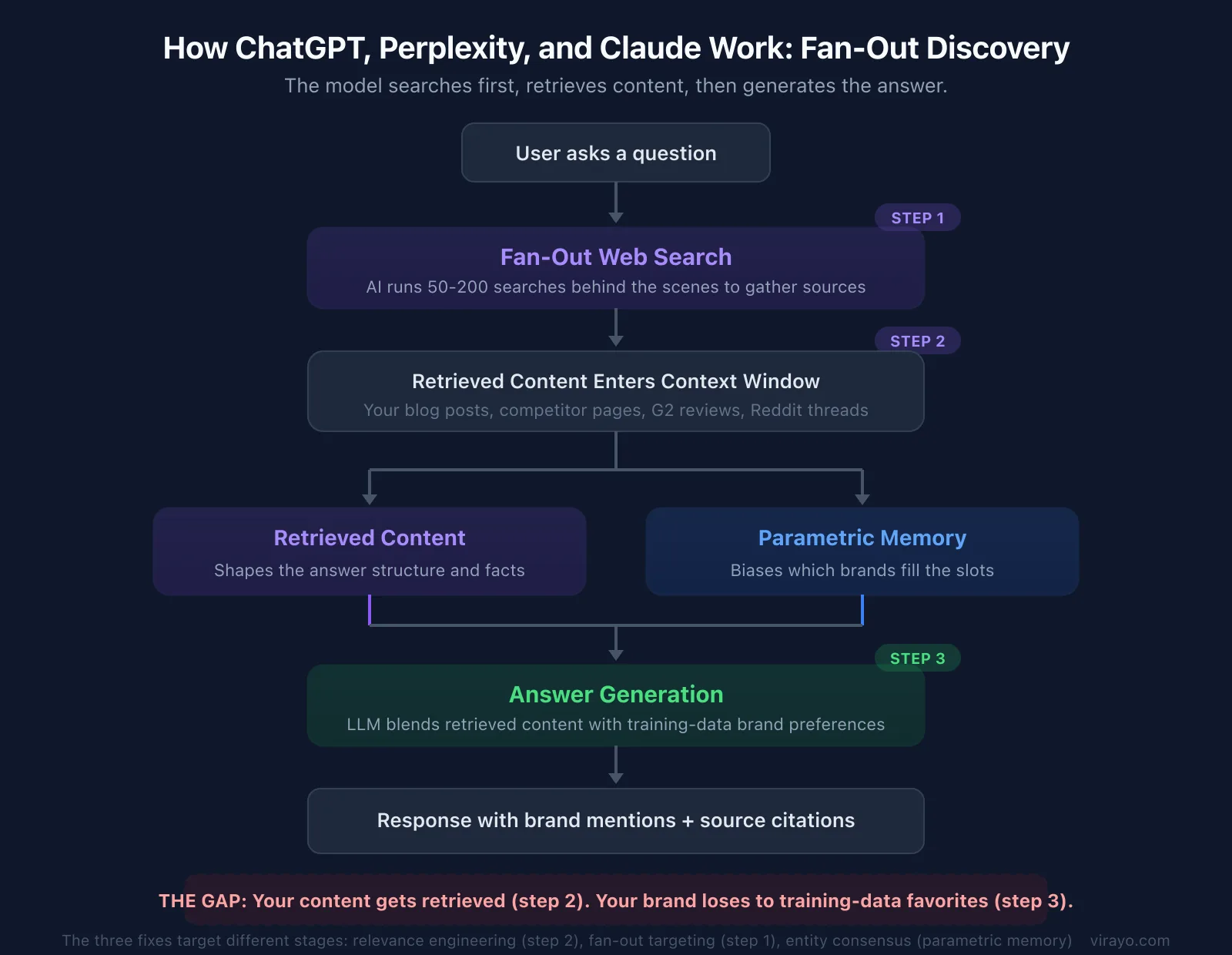
Our sourced-not-mentioned data is evidence for both models. A brand can be cited as a source in 36% of responses and mentioned in zero. The citation does not cause the mention. But the retrieved content is not irrelevant either. It is shaping the answer. The brand is just not making it from the source list into the actual answer.
Virayo's audit data shows which systems do this most. In the most recent weekly audit alone, 425 sourced-not-mentioned instances across 20 brands. Google AI Overview accounts for 43% of all cases. Claude Search and Perplexity split the rest at roughly 29% each. ChatGPT Search almost never does it. Less than 1%.
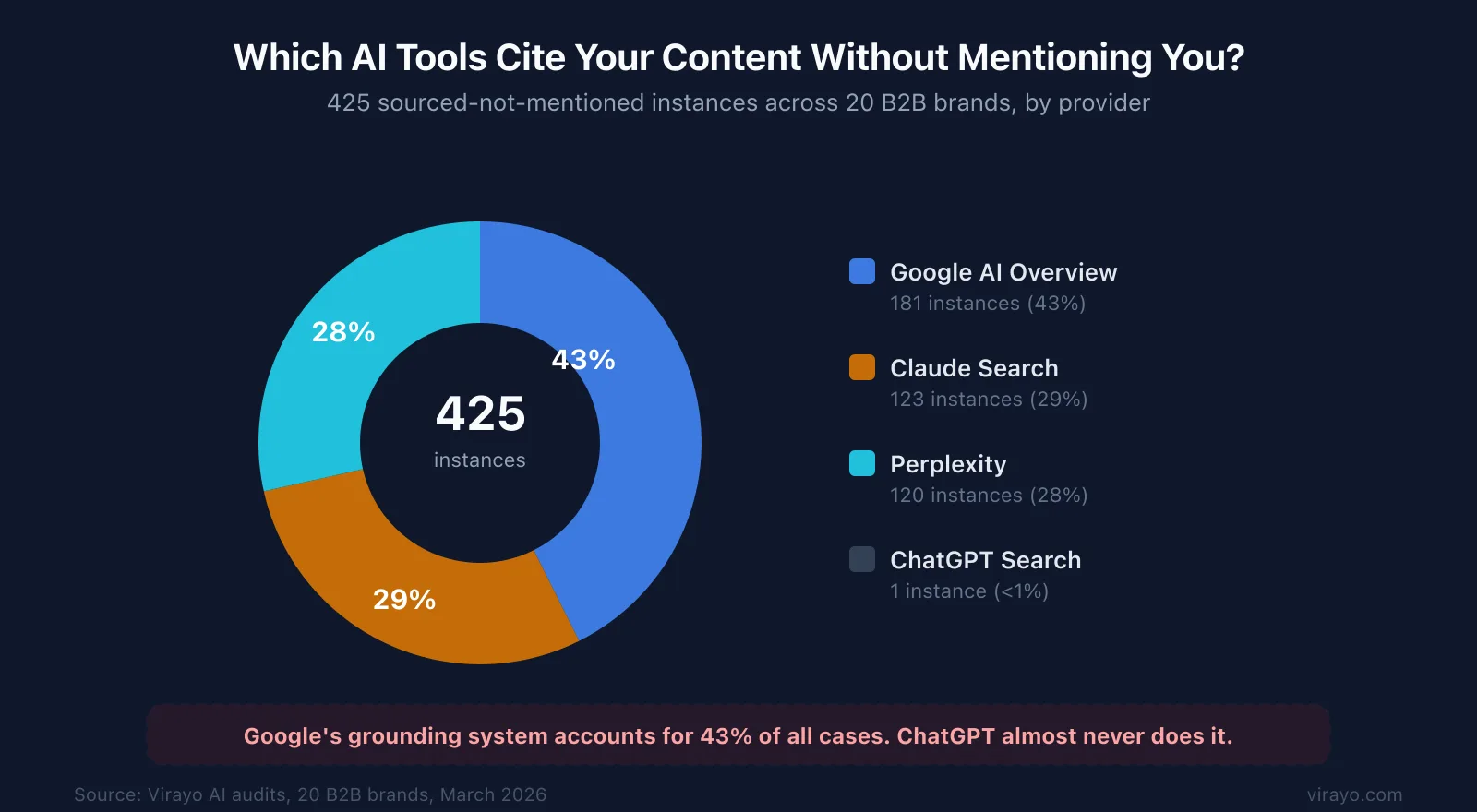
That tracks with the architecture. ChatGPT searches external indexes, reads what it finds, and builds the answer from retrieved content. When ChatGPT cites you, it actually read your content before deciding what to say. That is why your brand makes it into the response.
Princeton's GEO research confirms that content structure matters: the top optimization methods improved AI visibility by 30-40%. Keyword stuffing performed 10% worse than doing nothing.
The practical distinction matters because it tells you where to intervene. If this were purely a training-data problem, you would have to wait months for model updates and hope enough third-party signal accumulated to shift the model's defaults. But because the AI tools buyers actually use retrieve content before generating, you can fix a meaningful portion of the gap by changing what the AI reads at query time. That is what makes the first two approaches below work. The third approach builds the broader signal over time.
So how do you close the gap? We're working on three approaches with clients right now.
1. Relevance engineering on the pages they're already citing
When AI search tools retrieve your page, they extract the passages most relevant to the user's query. They do not read the full page. If your brand name only appears in the header or the byline, it may not be in the passage that actually shapes the answer.
The fix is structural. Make your brand name grammatically inseparable from the extractable claims. "At [Brand], our monitoring approach starts with baseline profiling" instead of "Database monitoring should start with baseline profiling." When the AI extracts that chunk, your brand travels with the insight.
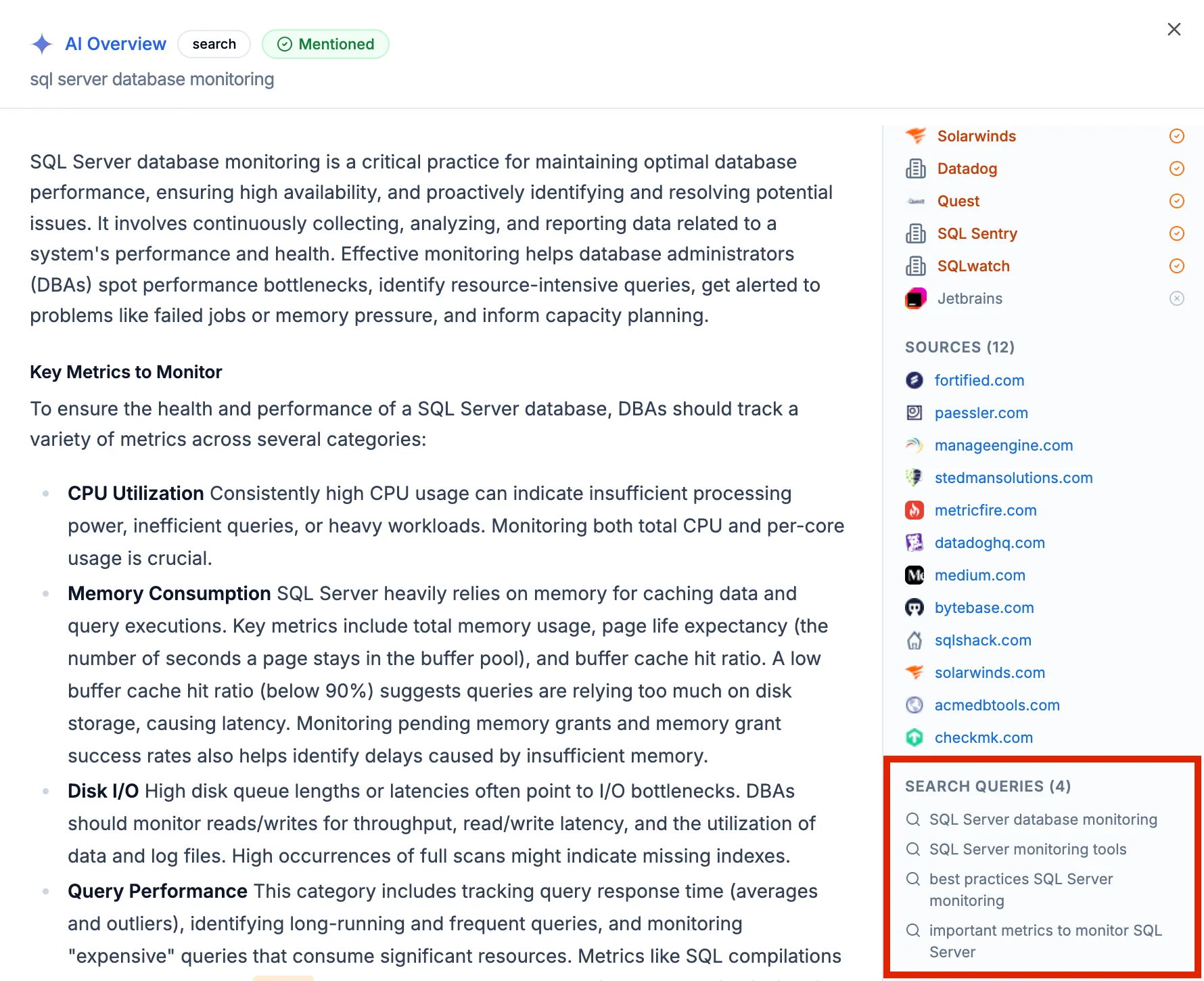
Semantic matching between the user's prompt and the page's content reveals the exact section the LLM is most likely reading. If your brand isn't in that section, the rest of the page doesn't matter. Virayo's guide to getting cited in AI search goes deeper on this.
Here is a real example. A database tools company has a blog post titled "Top Performance Monitoring Solutions." Claude, Perplexity, and Google AI Overview all cite it when users search "sql server database monitoring." The post compares 10 tools, including theirs. But the comparison section reads like a neutral third-party review. The brand name appears in the page header and the product listing, not in the analytical paragraphs the LLM extracts. The AI pulls the comparison framework, recommends Redgate and SolarWinds by name, and links back to the blog as its source.
The fix for that specific page: restructure the comparison so the brand's product is the analytical lens, not just one row in a table. "At [Brand], we benchmark monitoring tools against five criteria we use in our own infrastructure" reframes the entire page around the brand's authority.
2. Targeting the searches you can't see
When buyers ask AI tools about field sales software, the AI does not just search "field sales software." Across a single audit cycle, we captured 119 unique web searches that AI tools ran behind the scenes for one brand's category. Things like "best field sales CRM app offline mode routing territory management 2026" and "G2 field sales software best rated Badger Maps SalesRabbit."
Virayo captures these. Each AI tool's grounding queries reveal what it's actually looking for in your category. iPullRank has a great breakdown of how this works across platforms. There are two flavors. Grounding queries are narrow: 3-5 searches that validate an answer the AI is already forming. Google calls these grounding queries. They look like this: tight variations of the original question. Fan-out queries are broader: 10-30+ exploratory searches per provider that build the answer from scratch. ChatGPT and Claude search queries look like this: long-tail comparisons, specific product names, review site lookups.
ChatGPT, Perplexity, and Claude do not own a web index at that scale (though some may be building them). When they search, they are genuinely discovering information. Their queries are broader, more exploratory, and more numerous.
This matters for the sourced-not-mentioned gap because it tells you which fix to prioritize by platform. For fan-out systems like ChatGPT and Perplexity, relevance engineering and fan-out targeting work because the retrieved content genuinely shapes the answer. For grounding systems like Google AI Overview, entity consensus carries more weight because the model leans more heavily on what it already knows rather than what it discovers at query time.
Your keyword tracker sees neither type. Your rank tracker does not track them. But these are the searches that determine whether you appear in the final answer.
The Princeton GEO research found that the top optimization methods improved visibility by 30-40%, with statistics, source citations, and quotations all outperforming baseline. Keyword stuffing performed 10% worse than doing nothing. The content that wins isn't optimized for keywords. It's optimized for the specific sub-queries the AI generates internally. We break down more of these strategies in our GEO guide.
If you're also seeing organic traffic shifts alongside these AI visibility gaps, our December 2025 core update analysis covers how AI Overviews are compounding the problem.
3. Building the pattern that makes you mention-worthy
This is the longest play and the most important one. AirOps research found that 85% of brand mentions in LLM responses come from third-party pages. Not your website. G2 reviews, comparison articles, Reddit threads, analyst reports, news coverage.
SE Ranking's research across 129,000 domains found that brands on review platforms are 3x more likely to be cited by ChatGPT. G2 alone accounts for 22.4% of share of voice for software queries across major AI tools. A 10% increase in G2 reviews correlates with a 2% increase in LLM citations.
For the online proofing company with a 21% sourced-not-mentioned rate, we looked at where the citations were coming from. 94% of the URLs that LLMs cited when discussing online proofing tools pointed to sites the brand does not own. G2 reviews. Capterra listings. Competitor blog posts comparing tools. The LLMs are telling this brand's story using other people's words. And those words do not always position the brand the way it would position itself.
At Virayo, we call this mechanism entity consensus. When multiple independent sources describe your brand consistently in the same category, solving the same problems, the LLM treats that as a high-confidence pattern. That's how brands cross from "citation-worthy" to "mention-worthy." No single page will get you there. The web has to agree on who you are.
What this doesn't capture
The sourced-not-mentioned (SNM) rate measures what's observable: responses where your domain appears in the citations, but your brand is not mentioned in the answer text. It does not capture cases where your content may have influenced a response without being cited.
AI outputs are probabilistic. The same query can produce different answers across runs, providers, and prompts. To account for this, we measure rates across 7 AI providers and 25+ prompts per brand, collected at regular intervals via API without personalization signals (e.g., no login state or conversation history), which removes most user-specific variation.
These numbers are directional, not deterministic. But at sufficient sample sizes, stable patterns emerge. A 30% SNM rate across 100+ responses is a reliable signal to identify attribution gaps and act on.
Closing the gap
These three layers work together. Fix your own pages so the AI can't extract the insight without your brand name. Create content that ranks for the grounding and fan-out queries the AI actually runs. And build the third-party signal density that increases your chances of appearing across the sources AI tools retrieve.
The field sales company with a 30% sourced-not-mentioned rate has strong content. The AI proves that every time it cites their pages. What they don't have is the structural positioning and entity consensus that makes an LLM say their name out loud.
How to check your own sourced-not-mentioned rate
You can do a rough version of this in about 10 minutes.
Step 1. Pick five buying queries in your category. Not branded queries. Think "best [your category] software" or "[your category] tools for [use case]." The kinds of questions a buyer asks before they know your brand exists.
Step 2. Run each query in ChatGPT, Perplexity, and Google AI Overview. For ChatGPT and Perplexity, make sure search is enabled so the AI actually retrieves web results.
Step 3. For each response, check two things. First: is your brand mentioned anywhere in the answer text? Second: scroll to the citations or sources at the bottom. Is your domain listed?
Step 4. Count the responses where your domain appears in the citations but your brand is NOT mentioned in the answer. That is your sourced-not-mentioned count.
If you find even two or three instances across 15 responses (5 queries x 3 AI tools), you have the gap.
The automated version runs weekly across all seven major AI search tools, tracks the specific URLs being cited, captures the fan-out queries each tool runs behind the scenes, and trends it over time. That is what the Virayo AI platform does. But the manual check gives you a directional answer in 10 minutes.
Frequently asked questions
What is the difference between being cited and being mentioned by AI?
A citation means the AI found your page during its web search and listed it as a source, usually as a footnote link or in a references section. A mention means the AI named your brand in the actual response text. These are two separate systems, as the Seer Interactive research discussed above demonstrates. Your content can be valuable enough to cite without your brand being memorable enough to mention.
Which AI search tools have the highest sourced-not-mentioned rates?
In our data, Google AI Overview and Perplexity show the highest rates. Both tools actively search the web for every query, which means they find and cite more content. But because they synthesize answers from multiple sources, individual brands get diluted. ChatGPT with search enabled shows a similar pattern. Claude with search is newer but behaves the same way. The common thread: any AI tool that searches the web before answering can cite your content without mentioning your brand.
Does fixing your own content actually change what AI recommends?
For search-based AI tools (Perplexity, ChatGPT with browsing, Google AI Overviews), yes. These tools retrieve content in real time. Lily Ray demonstrated that AI Overviews picked up content from a blog post published an hour earlier. Content restructuring, where you make your brand inseparable from the extractable claims, directly affects what these tools pull into the response. For base model responses (ChatGPT without search, Claude without search), the change takes longer because it depends on the brand building enough web presence to shift the model's learned defaults over time.
How long does it take for content changes to show up in AI responses?
For search-augmented tools like Perplexity and Google AI Overview, changes can show up within days of the page being recrawled. For ChatGPT with browsing, it depends on when the underlying search indexes recrawl the page. We typically see changes reflected within one to two weeks for pages that already rank. For base model changes (affecting responses without web search), the timeline is tied to training data updates, which can take months. This is why the third fix, building third-party signal density, is the longest play but the most durable one.
Is this the same as what Seer Interactive calls ghost citations?
Similar concept, different angle. Seer Interactive coined the term ghost citations to describe responses where a brand's content earns citations but the brand itself is not mentioned. We arrived at the same phenomenon independently through our weekly audits and call it sourced-not-mentioned. The key difference is that we measure it as a rate per brand (e.g., 36% of search responses for a code protection company) and track the specific URLs, prompts, and providers involved. If you know which pages are being cited and which prompts trigger the gap, you know exactly what to fix.
You can keep publishing content that AI cites and your competitors benefit from. Or you can find out exactly where it's happening and fix the three things that determine whether AI says your name or someone else's.
We run the full sourced-not-mentioned analysis across all major AI tools using the Virayo AI platform. You'll see exactly which queries, which pages, and which competitors are getting credit for your work. See how it works.









